Data Center – What is in the Data Center?
In our last series, we defined what the Cloud is and how it is enabled by the Internet. We defined how the Internet is the infrastructure that connects private data centers at enterprises to the services hosted in The Cloud.
In this part of our series, we dive deeper into what a data center contains and how Cloud instances of data centers provide the services that we would have to provide in our own data centers if the Cloud did not exist.
Data Center – What is in the Data Center?
Data centers contain racks of servers, storage and internal network connections. The servers on one rack of a data center have to speak to other servers in another part of the data center. Please see Figure One for a depiction of the data center.
Figure One – Data Center Illustration

Data Center Tiers
Data Centers are laid out in logical “tiers” of functionality. These are generally:
1. Access Tier
Access tier – racks of servers that are connected to the Internet connections behind “firewalls” or devices that protect the data center from attack by hackers and other malicious entities on the internet.
Firewalls in an access tier will allow only web protocols (protocols designed to access
Generally, these devices balance network load, watch for excessive connections to the infrastructure (Denial of Service “DoS” attacks) and inspect traffic for well-known attack patterns.
2. Network SW/Internal Security Firewall layer
This layer of the architecture sits behind the access (web) layer and further protects the back-end infrastructure from attacks. Denial of Service attacks and Deep Packet Inspection are often implemented at this point in the architecture.
3. Compute servers
Compute servers – this layer of the network provides the actual business logic of applications and is allowed to access databases and other storage.
4. Storage servers
Storage servers – these servers are attached to the actual storage devices and provide connectivity to customer data. This is the deep heart of the data center and is purposely behind multiple servers and multiple firewalls to allow only authenticated access to customer data.
Only applications that can securely connect from the compute layer to the storage layer are allowed to obtain and send back user/customer data.
Please see Figure Two for a further illustration of these concepts:
Figure Two – Data Center Architecture

From this one can see that servers need to access storage resources that are hosted in other racks of the data center. To achieve this access internal network switches provide connectivity inside the data center.
A good example of this would be “front-end” web servers presenting application interfaces to users. The web servers connect to “back-end” servers which have the primary purpose of accessing databases or NoSQL infrastructure to obtain data that is required for users to analyze. The storage is for either structured data (database data) or unstructured data (files and emails or documents).
So basically a data center (either at an enterprise or one in the Cloud) requires:
- Servers
- Networking
- Storage
The big difference between an enterprise (private) data center and a Cloud service data center is that in the first case the enterprise has to buy, configure/provision and maintain private data center resources with their own capital, personnel, and other resources.
In the second
Understanding the complexity of data centers and servers is important to understanding the pros and cons of cloud vs. on-premise technology.
On-Premise Vs. Cloud
Understanding things like servers, data centers, and associated technology will help you understand the difference between cloud and on-premise technology.
Pros of on-premise deployment:
- More secure – all your data is behind your own firewall. Critical data is stored on-premise with no third-party access. Sensitive information such as healthcare or financial information can be stored on-premise with a very small chance of a breach.
- Physical control over server and hardware.
- Not reliant on internet access.
Cons of on-premise deployment:
- More expensive – companies need to purchase and store hardware on-site
- More prone to data loss in an emergency- on-premise deployments are not as easy to back up as cloud deployments
- Require an in-house IT team to physically manage the hardware and data (adding to the expenses)
- Harder to adjust storage space
Cloud Computing
Pros of cloud computing:
- No capital expenses – no physical hardware to purchase
- Data can be backed up regularly, which minimizes the chances of data loss
- Pay as you go – only pay for the options that you need.
- Don’t need to physically manage the hardware.
- Easy adjustment of storage space
- Data is stored remotely
Challenges of Cloud Computing
- Security – hacking into a cloud-based network can occur and the complexity of using another network to access services opens up potential security holes that can expose customer data
- Quick Data Growth can lead to loss of knowledge of what data is stored in the Cloud
- Storage growth can become expensive
- Synching Across Data Sources is difficult
- Setting up services in multiple clouds (AWS versus Microsoft Azure) can be difficult as different APIs and security standards vary between service providers
Cloud Services
Cloud Computing Services
Amazon EC2 (Elastic Compute Services)
Cloud computing services like EC2 (standing for Elastic Compute Services) allow one to request certain sizes and types of servers for use on behalf of an enterprise or individual.
When these are provisioned in the Amazon EC2 cloud the enterprise customer can upload programs that can be operated on the servers in the Amazon cloud. When these programs are run in the EC2 cloud they can access storage that is also maintained in the AWS cloud.
For
Amazon S3 Storage Services (Cloud Data Access)
Application Programming Interfaces (APIs) are the standard methods that are used for applications in an enterprise to access Cloud services. The Amazon S3 Storage Services allow applications in the enterprise data center to create data objects (files) in an Amazon AWS cloud storage service.
In AWS S3 the storage is organized as “buckets” which contain “objects” or files.
Buckets
A bucket is a container (like a folder on your Mac or a folder in Windows) that holds your files.
A bucket in Amazon S3 is something like: “
Objects
Files created by customer applications become Amazon AWS S3 objects resident in the AWS Cloud. The object created is named “photos/
Object Addresses and the API
The calls from programs in an enterprise use a “URL” that allows the program to create, find and delete objects from the bucket. Such a URL would be:
URL http://johnjones.s3.amazonaws.com/photos/sarah.jpg
{kind=link}
Which means: “go to the “s3.amazonaws.com” service and use the HTTP protocol to get object “photos/sarah.jpg”. The program goes to a certain service: “s3.amazonaws.com” and accesses a bucket and a certain object in that bucket (/photos/sarah.jpg”).
A program uses an API to work with these objects in an AWS S3 service location.
Amazon S3 Storage API Example
The Amazon AWS S3 API is a REST API which means that certain
To create a file:
POST URL http://johnjones.s3.amazonaws.com/photos/sarah.jpg
To read a file:
GET URLhttp://johnjones.s3.amazonaws.com/photos/sarah.jpg
To update a file:
PUT URLhttp://johnjones.s3.amazonaws.com/photos/sarah.jpg
To delete a file:
DELETE URLhttp://johnjones.s3.amazonaws.com/photos/sarah.jpg
One can see that this simple convenient API can allow enterprise programmers to easily create, update and when needed delete file objects in the Cloud S3 service offered by Amazon.
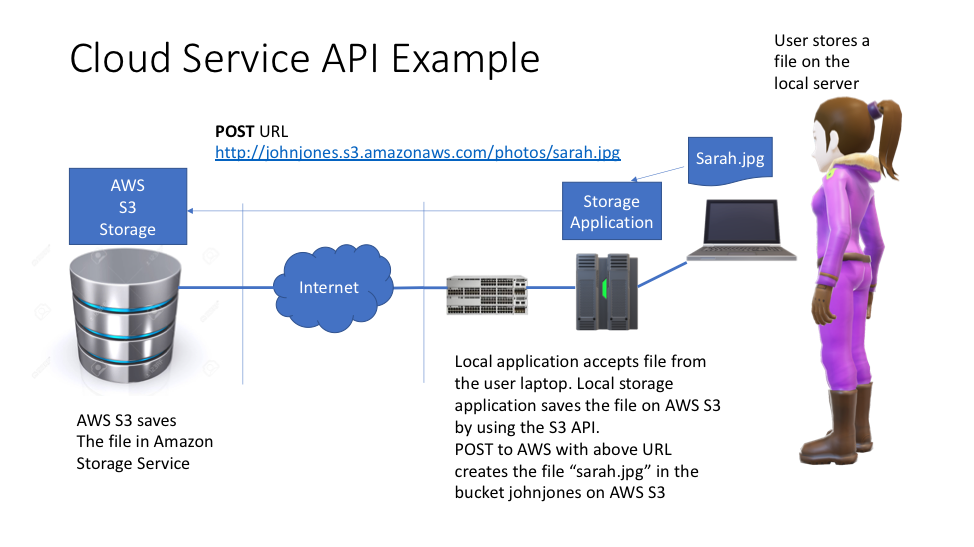
Figure Three shows a local user saving a file on a local server that then uses the AWS S3 API to save the locally created object in the AWS S3 service using the API.
Figure Three – Amazon AWS S3 API Example
Conclusion
This post should give the reader an appreciation of how a Cloud service differs from an on-premise enterprise data center and what it would take to
Finally, it should provide an insight into how the enterprise can use the AWS API to work with storage and create, update and delete objects in the AWS S3 cloud.